Introduction
Imagine you are a teacher standing in front of rows of students. You whisper something to the first row, and they pass the message forward row by row until it reaches the last row. You then approach the last row and ask them what they know. Based on their answer, you correct them. They then blame the row in front of them proportionally to how much that row influenced their answer. Each row tries to correct itself and passes the blame further forward, until the correction reaches the very first row. You continue to do the same process until the last row of students satisfy you with their answer.
If you have understood this analogy then I assure you that you have the wetware to understand how a multilayer perceptron does because this is roughly how a multilayer perceptron learns.
Perceptron And MLP
In the modern sense, a perceptron is a discriminative method to determine parameters of a linear classifier. The name discriminant suggests that the linear classifier is commonly used for classification, it makes a classification decision for each object based on a linear combination of so called features. Both features and parameters are elements of vectors, and to get a linear combination, linear classifier runs dot product on the vectors. The result is then put in a function, named activation, that converts the dot product of the vectors into desired output. This function varies depending on intentions like introducing nonlinearity, magnitude control and interpretability.
Linear classifier has decision boundary, where above values are positive and below values are negative. Decision boundary of a perceptron is at the origin of the high dimensional input space, it is stuck there forever. Unless you decide to add an intercept to the linear combination. Intercept also known as bias, provides necessary freedom to shift the decision boundary.
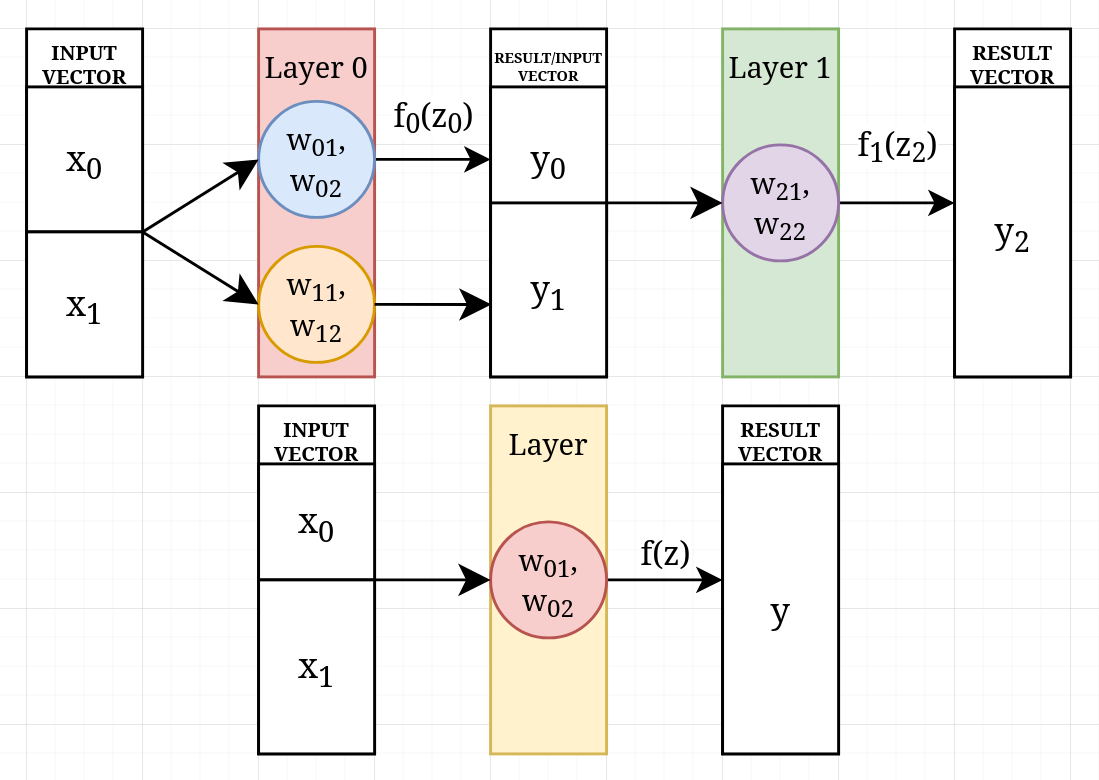
The original perceptron is not suitable for non linearly separable problems, so you might want to use multilayer perceptron, rather than a single layer perceptron. A multilayer perceptron is a kind of a feedforward neural network, it consists of a set of linearly stacked layers of various numbers of perceptrons in each layer. At each layer, perceptrons feed on the previous layer output. As an exception, the head of the stack feeds on manual inputs. The output of each layer comes from the perceptrons contained within it, and the number of perceptrons in a layer determines the size of the perceptron parameters in later layers.
It is vital to consider both input dependent perceptron output variety and differentiability due to the fact that the original perceptron learning method does not scale to multilayer perceptron so backpropagation is needed. Choosing activation function type for layers also becomes important. There is a chance for the perceptron parameters to converge on each other, so model can not distinguish some patterns. This will hinder learning and removes the advantage of multilayer. So using a nonlinear activation function for each layer must be considered, for the last layer the choice depends on the task.
The measure of wrongness of the mlp can be computed with a loss function. After each training step if the model’s answer is measured with a loss function, it will show how well the model has learned. SE for MSE is used for regression tasks and Cross-entropy is used for classification tasks.
Backpropagation is a method for gradient computation. In multilayer perceptron, each layer’s perceptron is responsible for the answer. This responsibility is called delta and can be calculated with the calculus chain rule to derive weight gradients and use in parameter update. It computes the last layer deltas by using the partial derivative of loss function for the answer, and uses each delta to compute the previous layer deltas. After computation for deltas at each layer, calculates the weight gradient by multiplying the delta by the corresponding input, then scales the parameter update by the learning rate.
Linear Classifier
Below is the mathematical formula explaining what a single perceptron does.
Features are a vector and represented as a single column matrix. This column contains what you try to make the mlp learn. After the training, it contains only inputs. Parameters are also a vector but it is a transposed one, expressed as a single row matrix. This row contains a perceptron’s weights. The shapes are telling us that if we multiply matrices we must multiply elements with each other in corresponding order and add them up. This way each perceptron produces a single scalar for the next layer.
Intercept/Bias
If you add a variable to dot product then linear classifier becomes . This variable is often called bias and it provides the necessary freedom because it shifts the decision boundary and does not depend on any input value.
Say you are classifying whether a student passes or fails based on one feature, hours studied. If the perfect boundary is 3 hours then every student above 3 hours would be successful. Without bias you would stuck at the origin so if a student that is studied more than 0 hours would be classified as passes. So with bias you have that necessary freedom to shift the boundary.
Bias can be random at initial stage, it will also get updated by perceptron deltas at the backpropagation.
State of The Parameters
Usually, every parameter is random at initial stage. This means all of the perceptrons will be definitely wrong and will affect each other so the MLP will give a wrong answer.
Ownership of The Parameters
There are two different types of ownership, locality and usage. Locality is where perceptrons and their weights physically live in memory. Usage, how layers connect by consuming each other’s outputs. Every layer perceptron uses the previous layer’s output as its inputs, and this consumption is what creates the connection between them. So each layer perceptron provides its input from previous layer except the head.
Multilayerity
A linear classifier, the so called perceptron can only draw a single decision boundary on a high dimensional input space. This means a perceptron can have multiple inputs but lack of the capacity to geometrically separate opposite side located results.
Feedforward
Let’s say we have MLP and it needs to learn AND & XOR logic gates. I’ve drawn a hypothetical two high dimensional input spaces with their corresponding perceptron hyperplanes and answer location on the space. XOR is what I mean by non linearly separable problem.
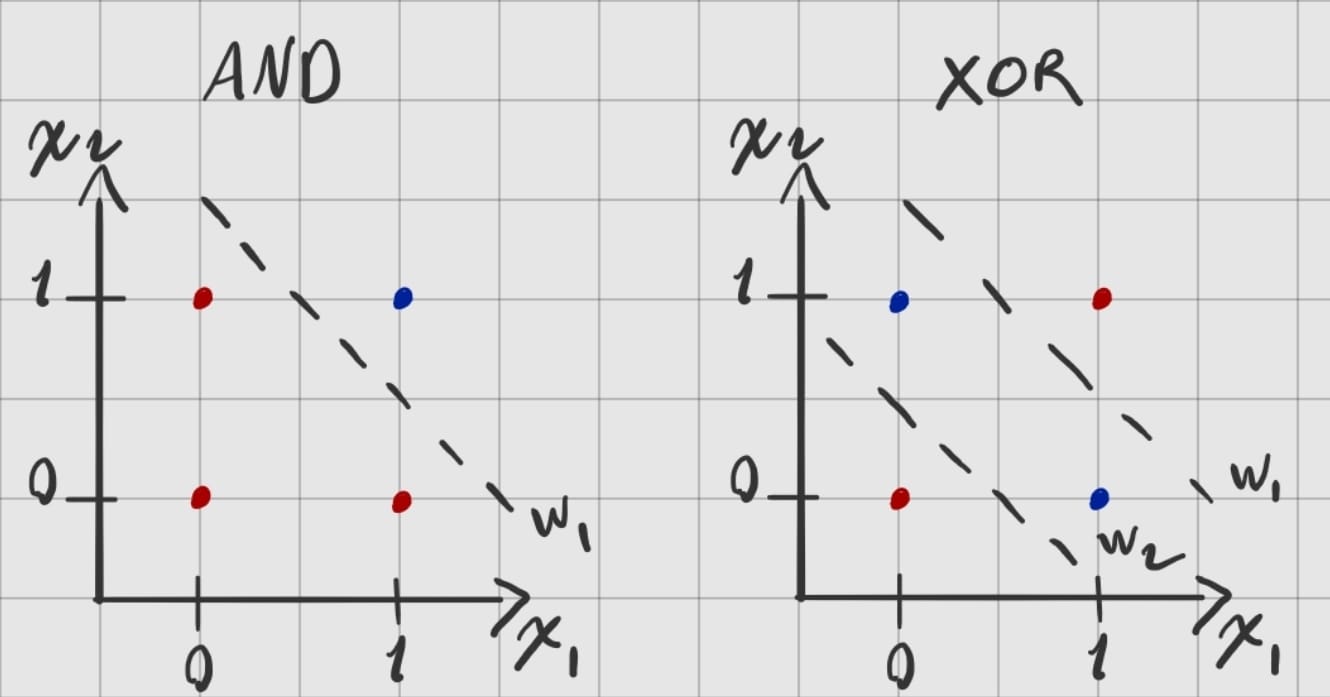
Each layer produces a vector in size of contained perceptron number to feed the later ones. Each input vector and the perceptron parameters have the same number of elements for the dot product. Parameter size depends on the input size, so if input size ever needs change, also the parameter size of a perceptron must change.
Backpropagation
The main idea of backpropagation is computing the last layer perceptron deltas with the above formula. The chain rule terminates at the perceptron’s weighted sum, so each delta is shared by all weights belonging to that perceptron. The formula for the last layer asks “how much does the Loss function change if I nudge the last layer’s output?”. The derivative of the loss answers this by indicating the direction and magnitude of the steepest increase, so gradient descent moves in the opposite direction to minimize the loss. When the loss is low enough, the model has learned well.
Later, compute inner layer deltas, hidden layer deltas, with the above formula. It resembles the inverse feedforward. Instead of multiplying weights by inputs, we multiply weights by the current layer’s deltas, then multiply by the activation function’s derivative at that layer due to the chain rule. After getting all layer deltas, gradient descent must be applied by starting from the last layer with below formula.
Conclusion
You might not have a clear model after reading all of this, and I understand how that feels. Maybe you are confused or have questions. If you are curious and stubborn enough, I promise you will build a much cleaner mental model. Let me tell you, this isn’t the first draft, and on each draft I’ve filled the gaps in my own mental model.